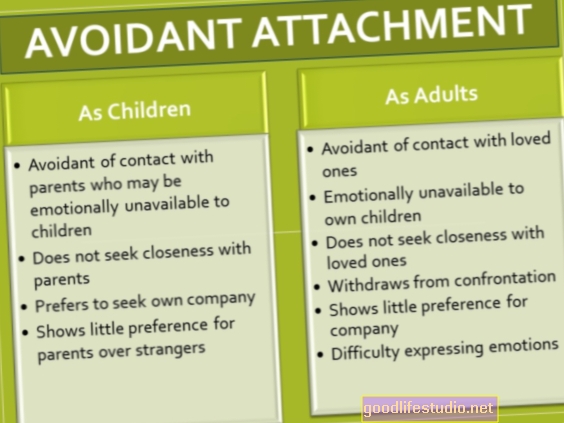
Gehirnbildgebung und maschinelles Lernen können helfen, das Risiko von psychischen Erkrankungen vorherzusagen
Forscher kombinieren Bildgebungsdaten des Gehirns und Supercomputer, um Muster in Neuroimaging-Daten zu identifizieren, die dazu beitragen können, das Risiko für psychische Störungen wie Depressionen oder Demenz vorherzusagen.
Jedes Jahr sind mehr als 15 Millionen amerikanische Erwachsene oder etwa 6,7 Prozent der US-Bevölkerung von Depressionen betroffen. Es ist die häufigste Ursache für Behinderungen zwischen 15 und 44 Jahren.
Dr. David Schnyer, ein kognitiver Neurowissenschaftler und Professor für Psychologie an der Universität von Texas in Austin, sagte, die Fähigkeit, das Risiko für psychische Erkrankungen vorherzusagen, sei keine einfache Sache.
Er verwendet einen Supercomputer, um einen Algorithmus für maschinelles Lernen zu trainieren, der Gemeinsamkeiten zwischen Hunderten von Patienten mithilfe von MRT-Gehirnscans (Magnetresonanztomographie), Genomdaten und anderen relevanten Faktoren identifizieren kann, um genaue Vorhersagen des Risikos für Menschen mit Depressionen und Angstzuständen zu liefern .
Forscher haben seit langem psychische Störungen untersucht, indem sie die Beziehung zwischen Gehirnfunktion und Struktur in Neuroimaging-Daten untersuchten.
"Eine Schwierigkeit bei dieser Arbeit besteht darin, dass sie in erster Linie beschreibend ist. Die Hirnnetzwerke scheinen sich zwischen zwei Gruppen zu unterscheiden, aber es sagt nichts darüber aus, welche Muster tatsächlich vorhersagen, in welche Gruppe Sie fallen werden “, sagte Schnyer.
"Wir suchen nach diagnostischen Maßnahmen, die Ergebnisse wie die Anfälligkeit für Depressionen oder Demenz vorhersagen."
Im Jahr 2017 hat Schnyer in Zusammenarbeit mit Forschern verschiedener Universitäten eine Analyse einer Proof-of-Concept-Studie abgeschlossen, bei der Personen mit Major Depression mithilfe eines Ansatzes des maschinellen Lernens mit einer Genauigkeit von etwa 75 Prozent klassifiziert wurden.
Zu den Co-Ermittlern gehörten Dr. Peter Clasen (Medizinische Fakultät der Universität Washington), Christopher Gonzalez (Universität von Kalifornien, San Diego) und Christopher Beevers (Universität von Texas, Austin).
Maschinelles Lernen ist ein Teilgebiet der Informatik, in dem Algorithmen konstruiert werden, die „lernen“ können, indem sie ein Modell aus Beispieldateneingaben erstellen und dann unabhängige Vorhersagen für neue Daten treffen.
Die Forscher stellten eine Reihe von Trainingsbeispielen zur Verfügung, von denen jedes entweder zu gesunden Personen oder zu Personen gehört, bei denen eine Depression diagnostiziert wurde. Schnyer und sein Team haben in ihren Daten aussagekräftige Merkmale gekennzeichnet, und diese Beispiele wurden zum Trainieren des Systems verwendet.
Ein Computer scannte dann die Daten, fand subtile Verbindungen zwischen unterschiedlichen Teilen und erstellte ein Modell, das der einen oder anderen Kategorie neue Beispiele zuweist.
In der Studie analysierte Schnyer Gehirndaten von 52 behandlungssuchenden Teilnehmern mit Depressionen und 45 Teilnehmern der Gesundheitskontrolle. Um die Gruppen zu vergleichen, haben sie eine Untergruppe depressiver Teilnehmer mit gesunden Personen nach Alter und Geschlecht verglichen und die Stichprobengröße auf 50 erhöht.
Die Teilnehmer erhielten DTI-MRT-Scans (Diffusion Tensor Imaging), mit denen Wassermoleküle markiert werden, um zu bestimmen, inwieweit diese Moleküle im Laufe der Zeit mikroskopisch im Gehirn diffundieren.
Die Forscher verglichen die resultierenden Messungen zwischen den beiden Gruppen und fanden statistisch signifikante Unterschiede. Anschließend reduzierten sie die beteiligten Daten auf eine Teilmenge, die für die Klassifizierung am relevantesten war, und führten die Klassifizierung und Vorhersage mithilfe des Ansatzes des maschinellen Lernens durch.
"Wir speisen Daten des gesamten Gehirns oder eine Teilmenge ein und prognostizieren Krankheitsklassifikationen oder mögliche Verhaltensmaßstäbe, z. B. Maße für negative Informationsverzerrungen", sagt er.
Die Studie ergab, dass die Gehirndaten depressive oder gefährdete Personen im Vergleich zu gesunden Kontrollen genau klassifizieren können. Es zeigte sich auch, dass prädiktive Informationen über Gehirnnetzwerke verteilt sind und nicht stark lokalisiert sind.
"Wir haben nicht nur gelernt, dass wir depressive gegenüber nicht depressiven Menschen anhand von DTI-Daten klassifizieren können, sondern auch, wie Depressionen im Gehirn dargestellt werden", sagte Beevers, Professor für Psychologie und Direktor des Instituts für psychische Gesundheit Forschung an der University of Texas, Austin.
"Anstatt zu versuchen, den Bereich zu finden, der durch Depressionen gestört ist, lernen wir, dass Veränderungen in einer Reihe von Netzwerken zur Klassifizierung von Depressionen beitragen."
Das Ausmaß und die Komplexität des Problems erfordern einen Ansatz des maschinellen Lernens. Jedes Gehirn wird durch ungefähr 175.000 Voxel dargestellt, und es ist praktisch unmöglich, eine komplexe Beziehung zwischen einer so großen Anzahl von Komponenten durch Betrachten der Scans zu erkennen.
Aus diesem Grund verwendet das Team maschinelles Lernen, um den Erkennungsprozess zu automatisieren.
"Dies ist die Welle der Zukunft", sagt Schnyer."Wir sehen auf der Konferenz immer mehr Artikel und Präsentationen über die Anwendung des maschinellen Lernens zur Lösung schwieriger Probleme in den Neurowissenschaften."
Die Ergebnisse sind vielversprechend, aber noch nicht eindeutig genug, um als klinische Metrik verwendet zu werden. Schnyer ist jedoch der Ansicht, dass das System durch Hinzufügen weiterer Daten, die sich nicht nur auf MRT-Scans, sondern auch auf Genomics und andere Klassifikatoren beziehen, viel bessere Ergebnisse erzielen kann.
„Einer der Vorteile des maschinellen Lernens im Vergleich zu herkömmlichen Ansätzen besteht darin, dass maschinelles Lernen die Wahrscheinlichkeit erhöhen sollte, dass das, was wir in unserer Studie beobachten, auf neue und unabhängige Datensätze angewendet wird. Das heißt, es sollte auf neue Daten verallgemeinert werden “, sagte Beevers.
"Dies ist eine kritische Frage, die wir gerne in zukünftigen Studien testen möchten."
Quelle: Universität von Texas in Austin, Texas Advanced Computing Center









-psychological-perspective.jpg)